BigBikeLoc : prédire la disponibilité des vélos Vélo’v et orchestrer tout le flux
Brief
BigBikeLoc est un écosystème modulaire de prédiction de disponibilité des vélos Vélo’v à Lyon. Le projet couvre toute la chaîne : préparation des données, entraînement multi-horizon, exposition en API, consommation par une interface utilisateur, automatisation métier (notifications e-mail), collecte de feedback et supervision ML.
Sommaire
- Problématique métier
- Méthodologie projet
- Contexte académique et équipe
- Technologies principales
- Architecture du système
- DevOps et infrastructure
- Stockage et base de données
- BBL_n8n : workflow, forms et mails
- Fonctionnalités clés
- Développement et défis
- Captures et démo locale
Dans les projets de mobilité urbaine, combiner modèles de machine learning, API de production et outils métier (alertes, formulaires, supervision) devient vite lourd à déployer et à maintenir. BigBikeLoc relie un pipeline d’entraînement, une API d’inférence, un frontal utilisateur, l’automatisation (n8n), la génération de contenu par LLM, l’envoi d’e-mails, la collecte de feedback et le suivi de la dérive des données.
flowchart LR
U["Usager"] --> FRONT["BBL_front (Streamlit)"]
FRONT --> API["BBL_FastAPI"]
API --> PRED["POST /predict"]
API --> FEED["POST /feedback"]
subgraph SRC["Sources de données"]
VELOV["Flux stations Vélo'v"]
METEO["Données météo"]
end
subgraph TRAIN["BBL_dataset_training"]
PIPE["Feature engineering + entraînement multi-horizon"]
REG["Versionnement d'artefacts"]
end
subgraph STOR["Volumes partagés"]
ART["shared/artifacts\nregistry.json, current, versions"]
DATA["shared/data\npredictions.jsonl, feedback.jsonl, retrain_requested.json"]
end
subgraph AUTO["BBL_n8n"]
N8N["Workflow n8n"]
FORMS["bbl-forms"]
MAILS["bbl-mails"]
LLM["bbl-ollama (tinyllama)"]
end
subgraph OBS["Observabilité"]
EVD["BBL_Evidently"]
DASH["Dashboards de dérive/qualité"]
end
VELOV --> PIPE
METEO --> PIPE
PIPE --> REG
REG --> ART
API --> ART
PRED --> DATA
FEED --> DATA
API --> N8N
N8N --> LLM
N8N --> MAILS
U --> FORMS
FORMS --> FEED
DATA --> WRK["retrain_worker"]
WRK --> ART
DATA --> EVD
EVD --> DASHProblématique métier
Le besoin de départ est très concret : à Lyon, lorsqu’un usager veut prendre un Vélo’v, il ne sait pas toujours à l’avance si des vélos seront disponibles à sa station au moment où il arrive.
Certaines tendances sont intuitives (par exemple, sur la Presqu’île, on observe souvent plus de vélos disponibles en soirée et moins le matin, en lien avec les usages pendulaires et la vie nocturne). Mais à d’autres moments, les variations sont difficiles à expliquer à l’oeil nu : météo, micro-événements locaux, déséquilibres entre stations, retards de régulation, etc.
L’objectif de BigBikeLoc est donc double :
- Prédire les pics et creux de disponibilité à plusieurs horizons (1 h, 3 h, 6 h, 12 h, 24 h).
- Intégrer des signaux explicatifs comme la météo et les dynamiques temporelles pour améliorer la robustesse des prévisions.
La finalité côté utilisateur est simple : réduire les situations frustrantes où une station est vide (pas de vélos) ou saturée (plus de bornes libres), et rendre le service plus fiable au quotidien.
Méthodologie projet
Le projet suit une approche incrémentale orientée valeur métier :
- Cadrage du besoin : définir les usages prioritaires (prévision court/moyen terme, notification proactive, observabilité).
- Définition du contrat de données : fixer un schéma commun entre entraînement, API et monitoring (features, horizons, version de modèle).
- Expérimentation ML : itérer sur les features temporelles, valider la robustesse par horizon et comparer les performances.
- Industrialisation : versionner les artefacts, sécuriser l’inférence et intégrer la boucle feedback -> réentraînement.
- Boucle d’amélioration continue : supervision, analyse de dérive et ajustement du pipeline selon les retours terrain.
Cette méthodologie permet de réduire les régressions entre la phase data science et la phase d’exploitation.
Contexte académique et équipe
Le projet a été réalisé dans le cadre du dernier semestre à Polytech Lyon, en équipe avec Agathe Minguet, Simon Morier, Timothé Longuet, Clément Ruchon et Ismail El Mouaddab.
Technologies principales
- Python : cœur du ML et du backend (entraînement, features, API, tests pytest).
- FastAPI : API REST d’inférence, schémas Pydantic, documentation OpenAPI (
/docs). - LightGBM : modèles par horizon (1 h, 3 h, 6 h, 12 h, 24 h), export joblib et alignement strict des features sur
model.feature_name_. - pandas / Parquet : données tabulaires, profil same-slot, artefacts versionnés.
- Hugging Face Datasets : chargement et fusion des jeux (Vélo’v, météo, etc.).
- Docker & Docker Compose : services conteneurisés, volumes partagés
shared/artifactsetshared/data. - Streamlit : interface web du frontal (port 8501 dans l’orchestration décrite).
- n8n : workflows (webhooks, chaînage vers Ollama et envoi de mails).
- Ollama : modèle TinyLlama pour rédiger le corps des e-mails à partir des prédictions.
- Evidently : suivi / monitoring ML sur les données partagées avec l’API (port 8085).
Architecture du système
Le dépôt s’organise en plusieurs composants (souvent des dépôts Git distincts dans la pratique, mais regroupés sous un même workspace) :
BBL_dataset_training — producteur d’artefacts ML
Pipeline : chargement, nettoyage, features (lags, rolling, temporel, same-slot, encodage des stations), construction du dataset multi-horizon, entraînement spécialisé par horizon, export versionné sous shared/artifacts/ (registry.json, current/, versions/<version>/). Un worker de réentraînement surveille des fichiers de déclenchement, relance l’entraînement et active une nouvelle version sans écraser l’historique.
BBL_FastAPI — API d’inférence et boucle de feedback
Charge la version active via registry.json, reconstruit les features à l’inférence (feature_builder), sert POST /predict, journalise les prédictions en JSON Lines, reçoit la vérité terrain via POST /feedback, peut déclencher un réentraînement par fichier trigger (seuil de feedbacks, etc.), et recharge les modèles sans redémarrage complet (reload_if_needed, POST /admin/reload-model). Expose aussi la santé du service et des routes stations (liste, détail, recherche par nom).
BBL_Scripts — orchestration
Scripts start-all / stop-all (Linux, Windows) : création des dossiers partagés, réseau Docker BBL-network, ordre de démarrage des stacks (n8n, API, front, Evidently, etc.), vérifications (ports, Ollama, import de workflow n8n).
BBL_n8n — automatisation et notifications
n8n, service bbl-mails (SMTP), bbl-forms (formulaires / feedback côté web), Ollama. Un workflow typique : webhook → préparation du prompt → Ollama → formatage → envoi d’e-mail → réponse JSON (contenu_mail, email_sent, etc.).
BBL_front — application Streamlit
Application Streamlit pour consommer l’API côté utilisateur.
BBL_Evidently — monitoring
Tableaux de bord de monitoring sur les données exposées dans les volumes partagés avec l’API.
Les volumes shared/artifacts et shared/data font le lien contractuel entre entraînement, inférence, logs de production, feedbacks et triggers de réentraînement, sans coupler le code du trainer à celui de l’API par des imports croisés.
flowchart LR
U["Usager"] --> F["BBL_front (Streamlit)"]
F --> P["BBL_FastAPI /predict"]
P --> M["model_store + feature_builder"]
M --> A["shared/artifacts"]
P --> D["shared/data"]
N["BBL_n8n"] --> O["bbl-ollama"]
N --> S["bbl-mails"]
N --> R["bbl-forms"]
R --> FB["BBL_FastAPI /feedback"]
FB --> D
T["BBL_dataset_training"] --> A
W["retrain_worker"] --> DDevOps et infrastructure
La partie infra repose sur des principes simples mais robustes :
- Conteneurisation complète avec Docker Compose pour garantir la reproductibilité locale.
- Réseau Docker externe unique (
BBL-network) : tous les services communiquent par nom de conteneur (bbl-api,bbl-n8n,bbl-mails, etc.). - Orchestration scriptée (
BBL_Scripts/start-all) : création des dossiers partagés, création réseau, libération des ports 5678/3100, démarrage ordonné des stacks, vérification/pull du modèle Ollamatinyllama, import automatique du workflow n8n. - Volumes partagés :
shared/artifacts(modèles/versioning),shared/data(predictions/feedback/trigger retrain), plus volume persistant n8n (bbl-n8n-data) et Ollama (bbl-ollama-data). - Secrets et config par variables d’environnement (
SHARED_ROOT, seuil feedback retrain, SMTP / Mailtrap, etc.). - Monitoring ML avec Evidently alimenté depuis les fichiers de production/feedback.
Le choix d’une infrastructure modulaire permet d’isoler les composants et de faire évoluer l’architecture sans casser le flux global.
flowchart TB
DEV["Machine dev / serveur local"] --> START["start-all"]
START --> PREP["Prépare dossiers shared/artifacts + shared/data"]
START --> NET["Crée réseau Docker BBL-network"]
START --> PORTS["Libère ports 5678 / 3100"]
subgraph N8NSTACK["Stack BBL_n8n (docker-compose)"]
N8N["bbl-n8n:5678"]
FORMS["bbl-forms:3100"]
MAILS["bbl-mails"]
OLLAMA["bbl-ollama"]
N8NVOL["Volume bbl-n8n-data"]
OLLVOL["Volume bbl-ollama-data"]
N8N --- N8NVOL
OLLAMA --- OLLVOL
end
subgraph MLSTACK["Stack ML/Serving"]
API["bbl-api:8000"]
FRONT["bbl-front:8501"]
EVD["bbl-evidently:8085"]
ART["shared/artifacts"]
DATA["shared/data"]
API --- ART
API --- DATA
EVD --- DATA
end
START --> N8NSTACK
START --> API
START --> FRONT
START --> EVD
START --> OCHK["Check/Pull tinyllama"]
START --> IWF["Import workflow n8n"]
NET -.DNS Docker .-> N8N
NET -.DNS Docker .-> API
NET -.DNS Docker .-> FRONT
NET -.DNS Docker .-> EVD
NET -.DNS Docker .-> FORMS
NET -.DNS Docker .-> MAILS
NET -.DNS Docker .-> OLLAMA
FRONT --> API
API --> N8N
N8N --> MAILS
N8N --> OLLAMA
FORMS --> APIStockage et base de données
Le projet ne s’appuie pas sur une base de données relationnelle centralisée. La persistance repose sur des fichiers versionnés et des logs JSONL :
- Artefacts ML dans
shared/artifacts/:registry.json(source de vérité de la version active)current/(copie active)versions/<version>/(historique complet)- modèles
model_H{1,3,6,12,24}.joblib,station_encoder.joblib,same_slot_profile.parquet
- Données opérationnelles dans
shared/data/:production/predictions.jsonlfeedback/feedback.jsonlretrain/retrain_requested.json(+ lock worker)
Côté n8n, la plateforme conserve aussi son état interne dans un volume dédié (bbl-n8n-data).
Ce choix “file-based + volumes Docker” a été fait pour des raisons pragmatiques :
- Contrat simple entre services : les repos d’entraînement, d’inférence et de monitoring lisent/écrivent le même format de fichiers sans dépendre d’un schéma SQL partagé.
- Versioning ML natif : la structure
registry.json+current/+versions/reflète directement le cycle de vie des modèles, ce qui est plus naturel qu’une table relationnelle pour ce cas. - Déploiement local rapide : moins de composants à opérer au démarrage (
start-all), ce qui facilite la reproductibilité de l’environnement de démo. - Traçabilité explicite :
predictions.jsonletfeedback.jsonlrestent auditables facilement, y compris hors ligne.
En contrepartie, la gouvernance des données, les requêtes analytiques complexes et les garanties transactionnelles sont plus limitées qu’avec une base dédiée.
BBL_n8n : workflow, forms et mails
Le repo BBL_n8n regroupe trois briques complémentaires :
n8n (orchestration)
- Expose le webhook
generate-email. - Reçoit le payload backend (request_id, email, station, prédictions, etc.).
- Prépare un prompt, appelle Ollama (
tinyllama), formate un contenu final, puis déclenche l’envoi viabbl-mails. - Retourne une réponse structurée (
contenu_mail,email_sent,message_id).
bbl-mails (service d’envoi)
- Microservice Node/TypeScript (
/send,/health) basé sur Nodemailer. - Supporte deux providers : Mailtrap (par défaut) ou SMTP classique.
- Lit ses variables depuis l’environnement (
MAIL_PROVIDER,MAILTRAP_*,SMTP_*). - Reçoit le contenu final du mail depuis n8n et gère l’envoi effectif.
bbl-forms (collecte feedback)
- Interface React servie via Nginx (port 3100).
- Lit les paramètres de prédiction depuis l’URL (request_id, station, modèle, prédictions).
- Permet à l’utilisateur de sélectionner un horizon et de saisir la valeur réelle observée.
- Proxy Nginx :
/api/feedback→bbl-api:8000/feedback/api/*(autres appels) → webhooks n8n
Ce sous-système relie donc la notification sortante (mail) à la boucle entrante de vérité terrain (feedback), qui alimente ensuite le déclenchement de retrain.
flowchart TB
subgraph ART["shared/artifacts"]
R1["registry.json"]
C1["current/"]
V1["versions/version-id"]
R1 --> C1
V1 --> C1
end
subgraph DAT["shared/data"]
P1["production/predictions.jsonl"]
F1["feedback/feedback.jsonl"]
T1["retrain/retrain_requested.json"]
end
API1["BBL_FastAPI"] --> R1
API1 --> P1
API1 --> F1
API1 --> T1
WRK["retrain_worker"] --> T1
WRK --> V1
EVD["BBL_Evidently"] --> P1
EVD --> F1Fonctionnalités clés
- Prédiction multi-horizon pour une station et un instant donnés, à partir d’un historique horaire de disponibilité.
- Versionnement explicite des modèles : chaque publication est un dossier de version complet ;
registry.jsonest la source de vérité de la version active. - Journalisation production : une ligne JSONL par horizon prédit, traçabilité
request_idetmodel_version. - Boucle fermée feedback → réentraînement : accumulation des retours, seuils configurables, déclenchement asynchrone du worker d’entraînement, puis rechargement côté API.
- Découverte des stations Vélo’v : mapping ID / nom officiel (centaines de stations), recherche par libellé.
- Notifications intelligentes : chaînage n8n + LLM pour personnaliser le texte des e-mails à partir des prédictions.
- Formulaires et webhooks pour intégrer le flux métier (collecte, tests, démonstrations).
- Supervision ML avec Evidently sur les données partagées.
- Démarrage unifié via scripts d’orchestration et réseau Docker dédié pour la résolution de noms entre conteneurs (
http://api:8000,http://bbl-n8n:5678, etc.).
Développement et défis
Mettre en cohérence deux mondes (repo d’entraînement et repo API) impose un contrat d’artefacts disque et un contrat de payloads API stricts : ordre des features, horizons supportés, fichiers obligatoires à chaque version, pas de réentraînement dans le thread HTTP. La compatibilité avec Insomnia / Postman ou tout client REST est naturelle grâce à FastAPI et aux schémas documentés. L’intégration n8n, Ollama et SMTP ajoute la gestion des secrets (.env), des URLs de webhook (test vs production) et de la robustesse lorsque l’envoi d’e-mail est optionnel ou en échec.
Contraintes et problématiques techniques
- Données non stationnaires : l’usage des stations varie selon heure, jour, météo, vacances et événements ponctuels.
- Qualité de données hétérogène : trous, retards de remontée, valeurs atypiques, changements de catalogues stations.
- Découplage entraînement / inférence : nécessité d’un contrat fort sur les artefacts et les features pour éviter les incompatibilités.
- Contraintes temps réel : l’API doit rester réactive même lorsqu’un réentraînement est nécessaire (d’où les triggers asynchrones).
- Multi-horizon difficile : chaque horizon a sa dynamique propre, ce qui justifie des modèles spécialisés.
- Intégration multi-services : n8n, Ollama, SMTP, front et API introduisent des points de défaillance supplémentaires à superviser.
Limites actuelles du projet
- La prédiction reste sensible aux ruptures fortes (grève, incident réseau, saturation locale, événement massif non observé).
- Le modèle est performant sur des patterns récurrents, mais moins robuste sur des comportements très rares.
- La boucle feedback dépend de la quantité et de la qualité des retours terrain effectivement collectés.
- Le périmètre est centré sur Vélo’v Lyon : la généralisation à d’autres villes exige adaptation des features et recalibrage.
- L’usage d’un LLM pour la rédaction d’e-mails apporte de la flexibilité, mais nécessite des garde-fous de coût et de qualité de sortie.
- Dans la version actuelle documentée, les features météo existent dans le pipeline d’entraînement, mais la météo temps réel n’est pas encore branchée côté inférence MVP.
Captures et démo locale
Pour une démonstration locale : lancer Docker, exécuter le script start-all adapté à l’OS, puis ouvrir les services documentés (API sur le port 8000, Streamlit 8501, n8n 5678, formulaires 3100, Evidently 8085).
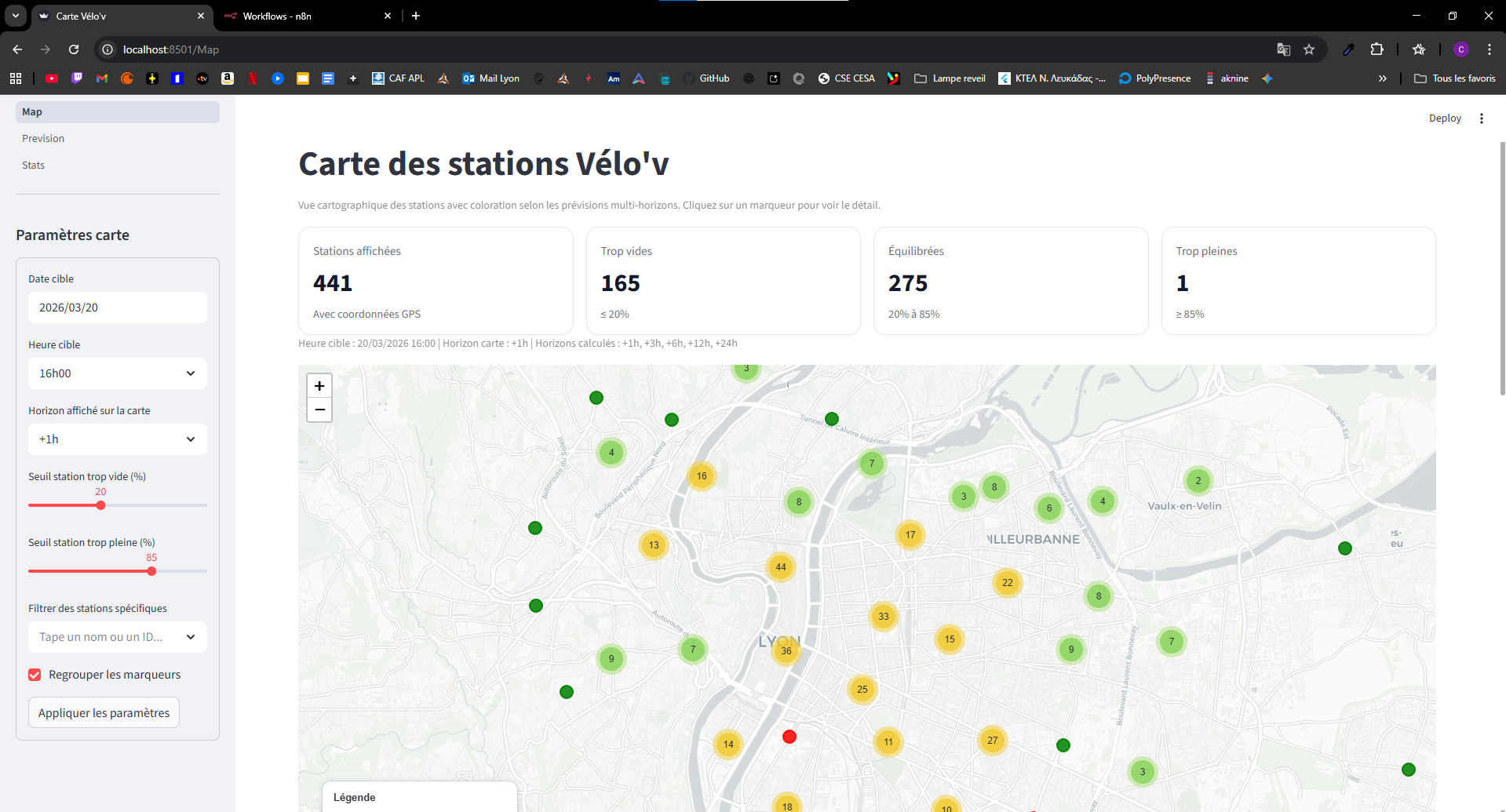
Légende — Capture 1 : carte des stations à risque pour orienter la décision terrain.
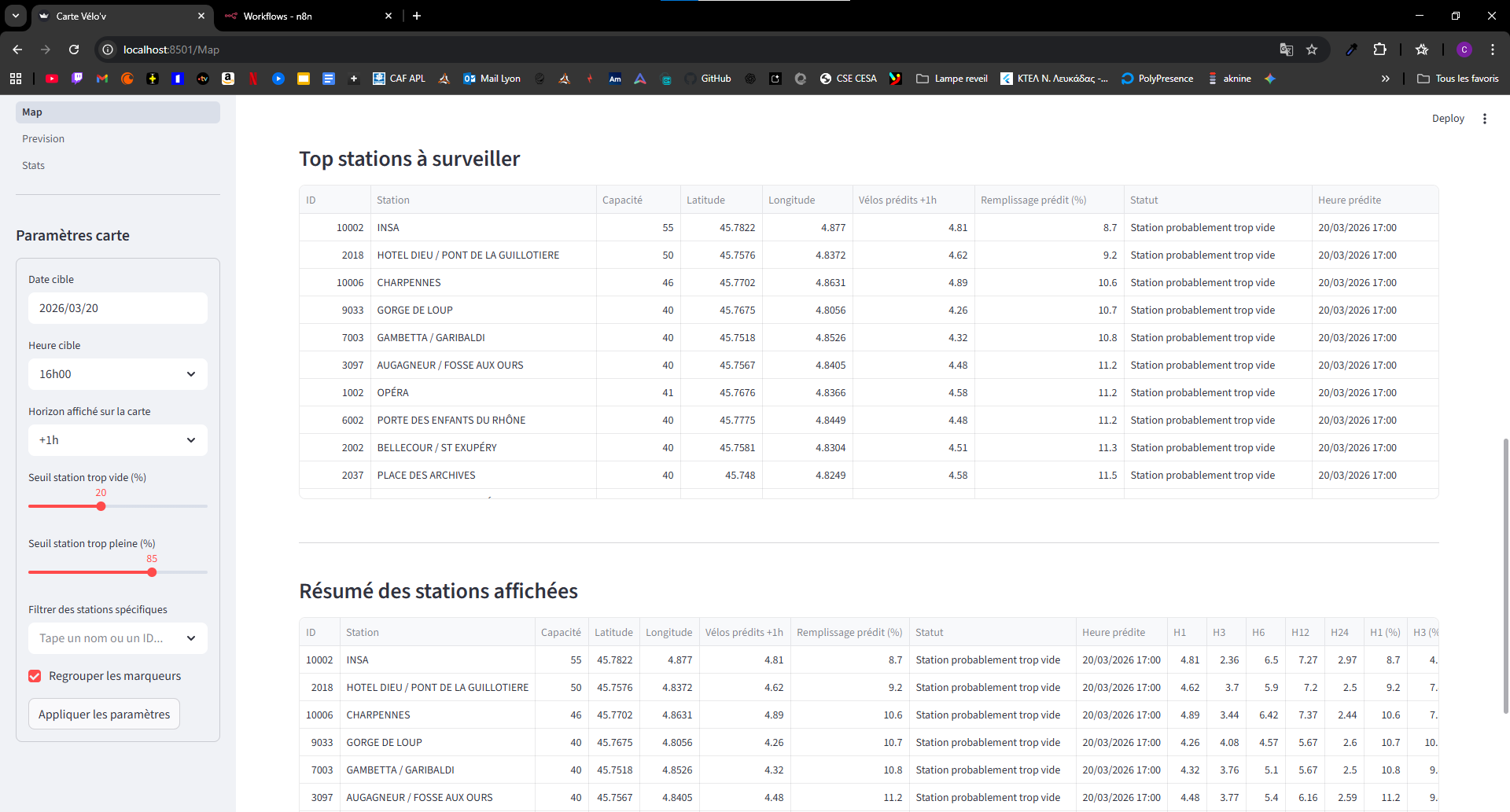
Légende — Capture 2 : priorisation des stations à surveiller pour anticiper les tensions.
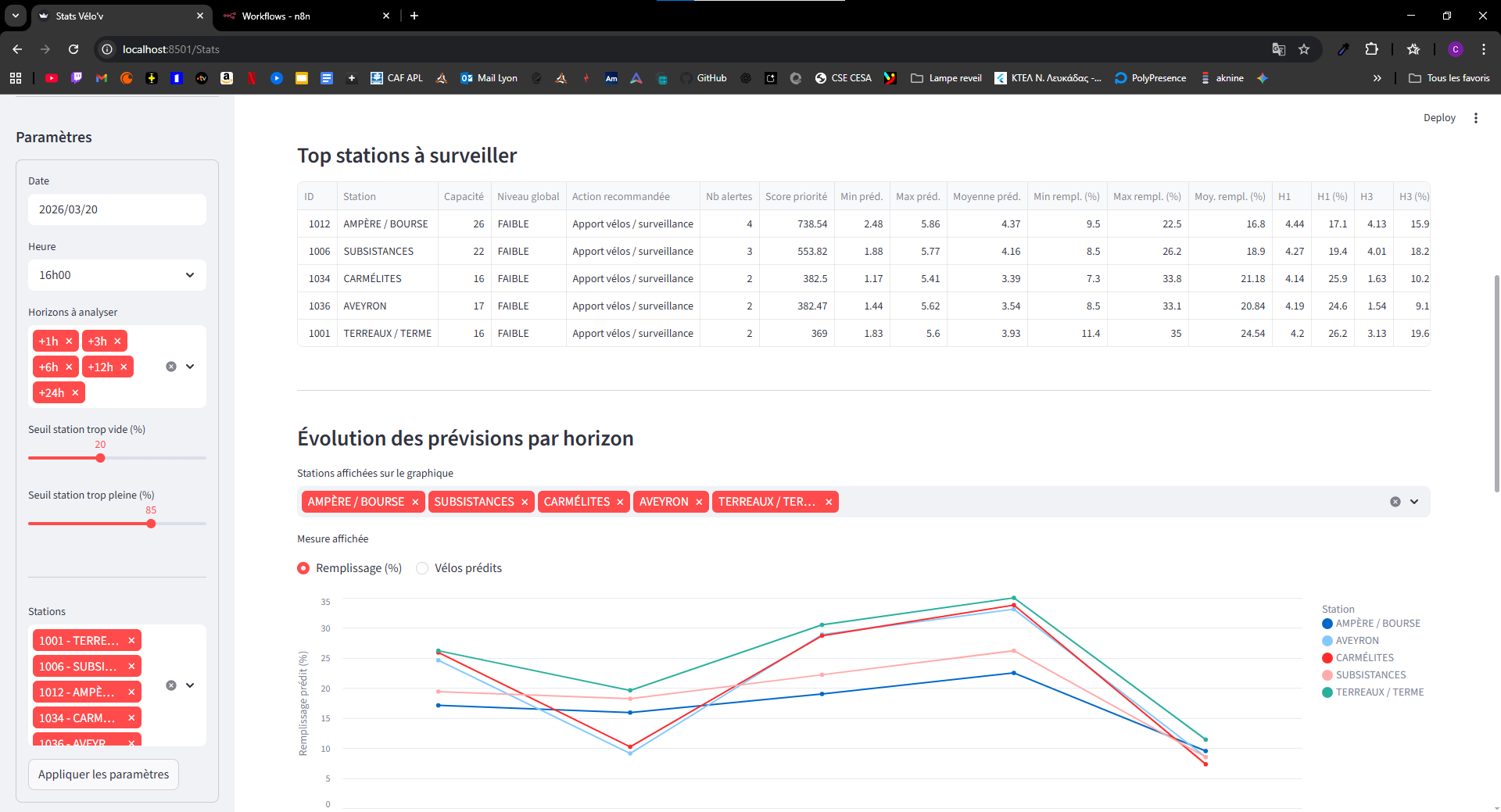
Légende — Capture 3 : évolution des prévisions pour planifier les actions par horizon.
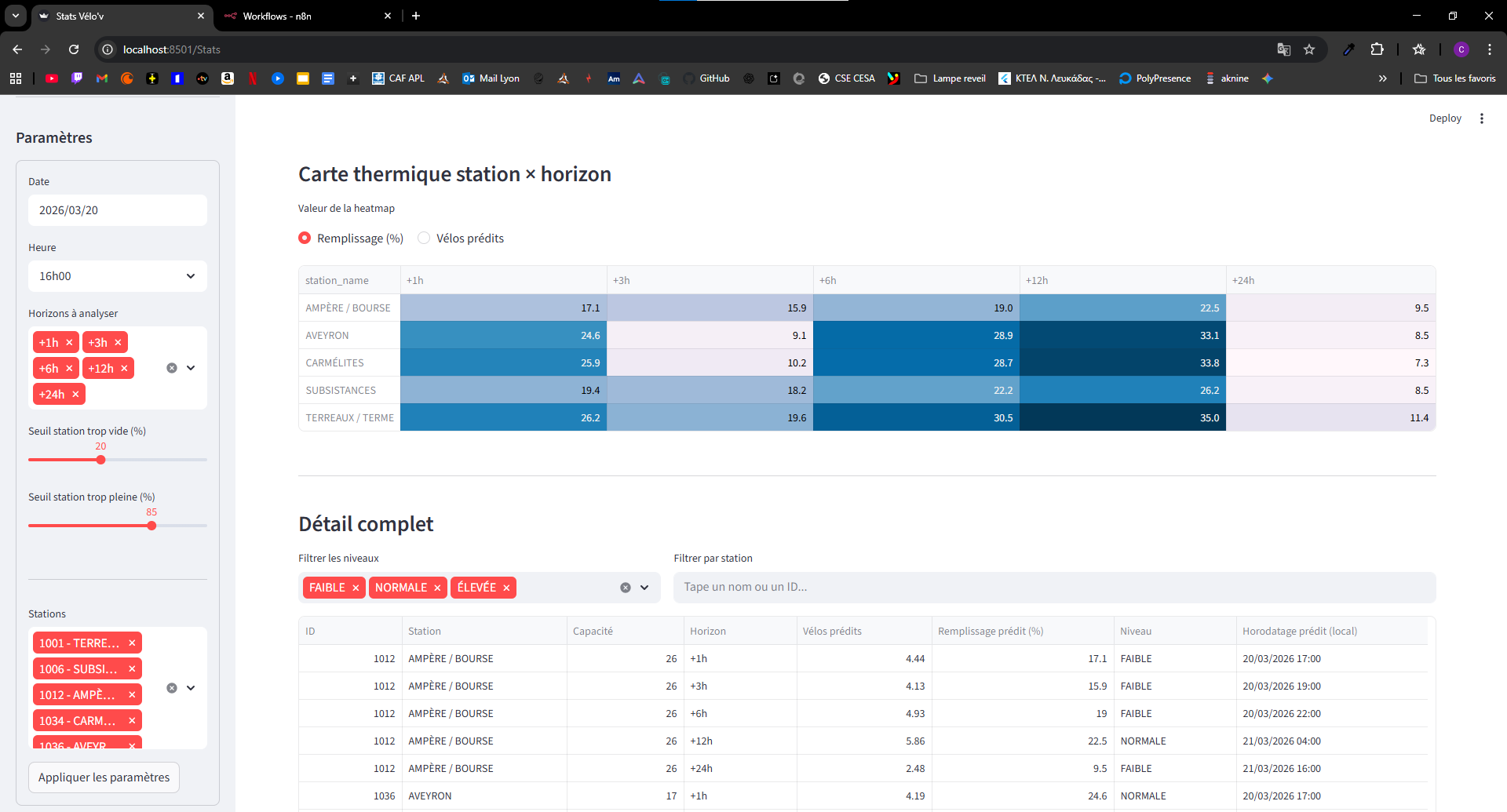
Légende — Capture 4 : vision consolidée des niveaux de service par station et horizon.
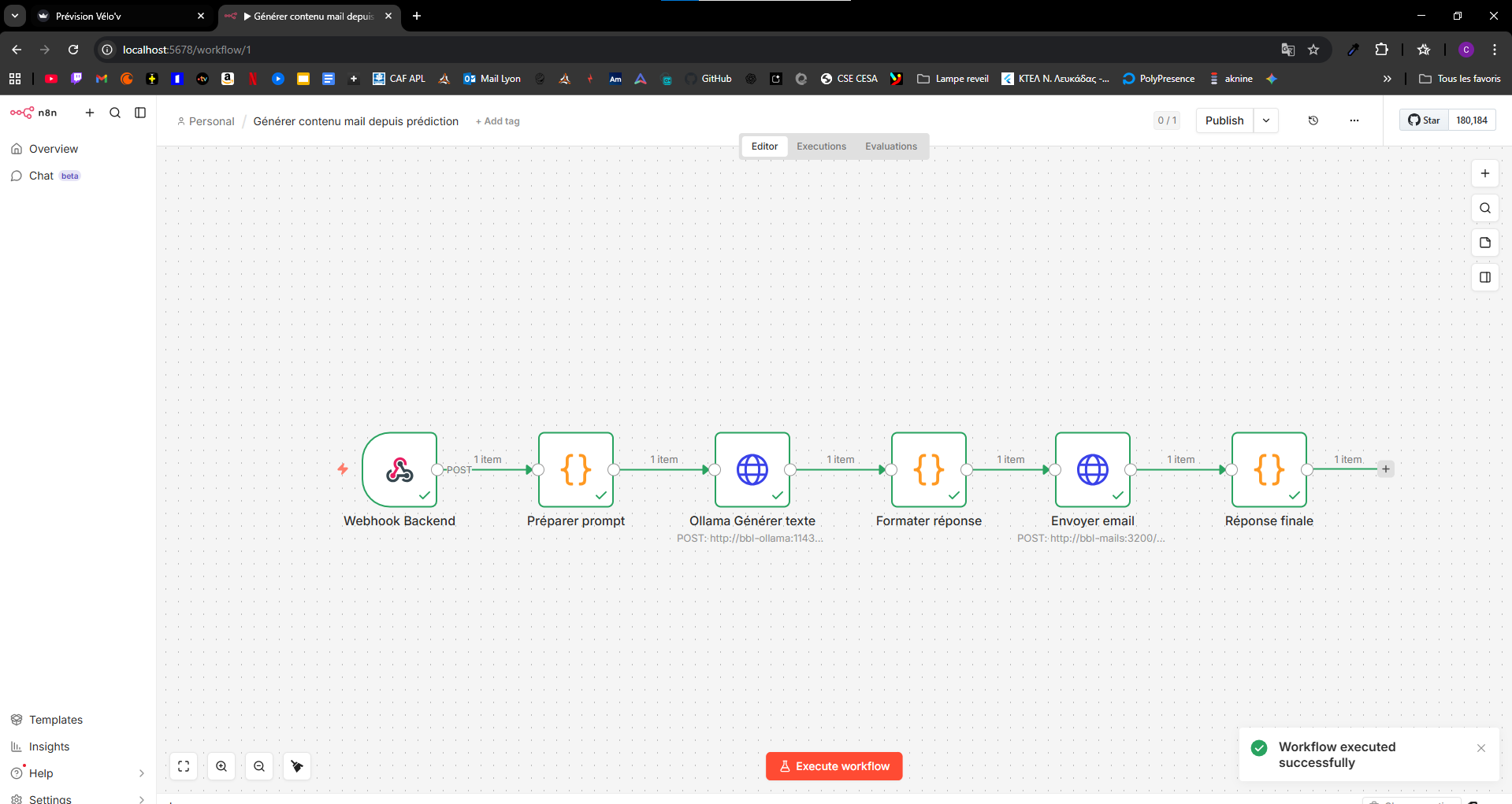
Légende — Capture 5 : automatisation des notifications pour informer les usagers en temps utile.
English version
Brief
BigBikeLoc is a modular system that predicts bike availability for the Velo’v network in Lyon. It includes end-to-end components: data preparation, multi-horizon model training, inference API, user app, workflow automation, feedback collection, and ML monitoring.
Table of contents
- Business problem
- Project methodology
- Academic context and team
- Main technologies
- System architecture
- DevOps and infrastructure
- Storage and data layer
- BBL_n8n: workflow, forms and mails
- Key features
- Development challenges
- Technical constraints
- Current limitations
- Screenshots and local demo
In urban mobility projects, combining machine learning models, production APIs, and business tools (alerts, forms, monitoring) quickly becomes complex to deploy and maintain. BigBikeLoc connects a training pipeline, an inference API, a user-facing frontend, workflow automation (n8n), LLM-based content generation, email delivery, feedback collection, and data-drift monitoring.
flowchart LR
U["User"] --> FRONT["BBL_front (Streamlit)"]
FRONT --> API["BBL_FastAPI"]
API --> PRED["POST /predict"]
API --> FEED["POST /feedback"]
subgraph SRC["Data sources"]
VELOV["Velo'v station feed"]
WEATHER["Weather data"]
end
subgraph TRAIN["BBL_dataset_training"]
PIPE["Feature engineering + multi-horizon training"]
REG["Artifact versioning"]
end
subgraph STOR["Shared volumes"]
ART["shared/artifacts\nregistry.json, current, versions"]
DATA["shared/data\npredictions.jsonl, feedback.jsonl, retrain_requested.json"]
end
subgraph AUTO["BBL_n8n"]
N8N["n8n workflow"]
FORMS["bbl-forms"]
MAILS["bbl-mails"]
LLM["bbl-ollama (tinyllama)"]
end
subgraph OBS["Observability"]
EVD["BBL_Evidently"]
DASH["Drift/quality dashboards"]
end
VELOV --> PIPE
WEATHER --> PIPE
PIPE --> REG
REG --> ART
API --> ART
PRED --> DATA
FEED --> DATA
API --> N8N
N8N --> LLM
N8N --> MAILS
U --> FORMS
FORMS --> FEED
DATA --> WRK["retrain_worker"]
WRK --> ART
DATA --> EVD
EVD --> DASHBusiness problem
The starting point is straightforward: in Lyon, when someone wants to pick up a Velov bike, they often do not know in advance whether bikes will still be available upon arrival.
Some patterns are obvious (for example, in the city center, bike availability often differs between morning and evening because of commuting and nightlife habits). But many fluctuations are harder to explain directly: weather effects, local events, rebalancing delays, and station-level imbalances.
BigBikeLoc addresses this with two goals:
- Forecasting peaks and drops in availability across multiple horizons (1 h, 3 h, 6 h, 12 h, 24 h).
- Using contextual signals such as weather and temporal dynamics to improve prediction quality.
The practical objective is to reduce frustrating cases where a station is empty (no bikes) or saturated (no free docks), and make the service more reliable for everyday users.
Project methodology
The project follows an iterative, value-driven approach:
- Problem framing around priority user journeys.
- Data contract design between training, serving, and monitoring.
- ML experimentation with horizon-specific validation.
- Production hardening through artifact versioning and safe reload paths.
- Continuous improvement loop from monitoring and user feedback.
Academic context and team
The project was developed during the final semester at Polytech Lyon, in a team with Agathe Minguet, Simon Morier, Timothe Longuet, Clement Ruchon, and Ismail El Mouaddab.
Main technologies
- Python: core of ML and backend (training, features, API, pytest tests).
- FastAPI: REST inference API, Pydantic schemas, OpenAPI docs (
/docs). - LightGBM: horizon-specific models (1 h, 3 h, 6 h, 12 h, 24 h), joblib export, strict feature alignment with
model.feature_name_. - pandas / Parquet: tabular data, same-slot profiling, versioned artifacts.
- Hugging Face Datasets: loading and merging source datasets (Velo’v, weather, etc.).
- Docker & Docker Compose: containerized services, shared volumes
shared/artifactsandshared/data. - Streamlit: web UI for end users.
- n8n: automation workflows (webhooks, Ollama chaining, email sending).
- Ollama: TinyLlama model used to generate prediction-based email content.
- Evidently: ML monitoring on shared production data.
System architecture
The workspace is organized into multiple components:
BBL_dataset_training: artifact-producing ML training pipeline with versioned outputs and retraining worker.BBL_FastAPI: inference API withPOST /predict, feedback endpoint, logs, model reload without full restart.BBL_Scripts: orchestration scripts (start-all/stop-all) for startup order, Docker network, and checks.BBL_n8n: automation stack with workflow orchestration, forms, email service, and Ollama.BBL_front: Streamlit frontend consuming API endpoints.BBL_Evidently: monitoring dashboards.
The shared volumes shared/artifacts and shared/data define the contract between training, inference, production logs, feedback loops, and retraining triggers.
DevOps and infrastructure
- Full Docker Compose setup for reproducible environments.
- Dedicated external Docker network (
BBL-network) for inter-service communication by container name. - Scripted orchestration (
start-all) to create shared folders/network, free required ports, start stacks in order, ensure Ollama model availability, and import n8n workflow. - Shared volumes for artifacts/data plus dedicated persistence volumes for n8n and Ollama.
- Environment-based configuration for API thresholds and mail providers.
- Evidently monitoring pipeline built from production JSONL logs and feedback JSONL.
flowchart TB
DEV["Developer machine / local host"] --> START["start-all"]
START --> PREP["Prepare shared/artifacts + shared/data folders"]
START --> NET["Create BBL-network"]
START --> PORTS["Free ports 5678 / 3100"]
subgraph N8NSTACK["BBL_n8n stack (docker-compose)"]
N8N["bbl-n8n:5678"]
FORMS["bbl-forms:3100"]
MAILS["bbl-mails"]
OLLAMA["bbl-ollama"]
N8NVOL["Volume bbl-n8n-data"]
OLLVOL["Volume bbl-ollama-data"]
N8N --- N8NVOL
OLLAMA --- OLLVOL
end
subgraph MLSTACK["ML/Serving stack"]
API["bbl-api:8000"]
FRONT["bbl-front:8501"]
EVD["bbl-evidently:8085"]
ART["shared/artifacts"]
DATA["shared/data"]
API --- ART
API --- DATA
EVD --- DATA
end
START --> N8NSTACK
START --> API
START --> FRONT
START --> EVD
START --> OCHK["Check/Pull tinyllama"]
START --> IWF["Import n8n workflow"]
NET -. Docker DNS .-> N8N
NET -. Docker DNS .-> API
NET -. Docker DNS .-> FRONT
NET -. Docker DNS .-> EVD
NET -. Docker DNS .-> FORMS
NET -. Docker DNS .-> MAILS
NET -. Docker DNS .-> OLLAMA
FRONT --> API
API --> N8N
N8N --> MAILS
N8N --> OLLAMA
FORMS --> APIStorage and data layer
The current implementation does not rely on a central relational database for core application flows. Persistence is primarily file-based and shared across containers:
shared/artifacts/for versioned ML artifacts (registry.json,current/,versions/<version>/, models, encoder, same-slot profile)shared/data/production/predictions.jsonlshared/data/feedback/feedback.jsonlshared/data/retrain/retrain_requested.json(+ lock file during worker execution)
n8n keeps its own runtime state in a dedicated Docker volume (bbl-n8n-data).
This “file-based + Docker volumes” choice is intentional:
- Simple contract across services: training, inference, and monitoring repos exchange data through shared files without a tightly coupled SQL schema.
- Natural ML versioning model:
registry.json+current/+versions/maps directly to model lifecycle management. - Fast local bootstrap: fewer moving parts to run with
start-all, which keeps local demos reproducible. - Explicit audit trail:
predictions.jsonlandfeedback.jsonlare easy to inspect and replay.
The trade-off is lower support for advanced analytical querying and transactional guarantees compared to a dedicated database stack.
BBL_n8n: workflow, forms and mails
n8n workflow orchestration
- Exposes
generate-emailwebhook. - Validates and transforms backend payload.
- Calls Ollama (
tinyllama) to generate analysis text. - Builds final mail body and triggers email sending via
bbl-mails. - Returns structured response (
contenu_mail,email_sent,message_id).
bbl-mails service
- Node/TypeScript microservice (
/send,/health) based on Nodemailer. - Supports Mailtrap or SMTP providers via environment variables.
- Handles actual mail transport and delivery status.
bbl-forms service
- React form app served by Nginx (port 3100).
- Reads prediction context from URL query params.
- Lets users submit observed ground truth for a selected horizon.
- Nginx proxy routes:
/api/feedback->bbl-api:8000/feedback- other
/api/*-> n8n webhooks
This closes the loop between prediction notification and feedback collection feeding retraining triggers.
flowchart TB
subgraph ART["shared/artifacts"]
R1["registry.json"]
C1["current/"]
V1["versions/version-id"]
R1 --> C1
V1 --> C1
end
subgraph DAT["shared/data"]
P1["production/predictions.jsonl"]
F1["feedback/feedback.jsonl"]
T1["retrain/retrain_requested.json"]
end
API1["BBL_FastAPI"] --> R1
API1 --> P1
API1 --> F1
API1 --> T1
WRK["retrain_worker"] --> T1
WRK --> V1
EVD["BBL_Evidently"] --> P1
EVD --> F1Key features
- Multi-horizon prediction for station availability at future time horizons.
- Explicit model versioning with
registry.jsonas the source of truth. - Production JSONL logging with
request_idandmodel_version. - Closed-loop feedback to retraining with threshold-based asynchronous retraining.
- Station discovery and station-name lookup utilities.
- Smart notifications through n8n + LLM email generation.
- Business workflow integration through forms and webhooks.
- ML monitoring with Evidently.
- Unified startup via scripts and a dedicated Docker network.
Development challenges
A major challenge was keeping training and API repositories aligned through strict disk artifact contracts and API payload contracts: feature ordering, supported horizons, mandatory files per version, and asynchronous retraining (never inside HTTP request threads). Integrating n8n, Ollama, and SMTP also required robust secret management (.env) and resilient behavior when email delivery is optional or fails.
Technical constraints
- Non-stationary demand patterns across hours, weekdays, weather and seasonal effects.
- Uneven data quality (missing values, delays, outliers, station metadata drift).
- Strict compatibility requirements between training artifacts and inference payloads.
- Real-time API constraints while retraining workflows must remain asynchronous.
- Different error profiles across forecast horizons requiring specialized modeling.
Current limitations
- Lower robustness on exceptional disruptions (major incidents, sudden network perturbations).
- Performance depends on how representative recent historical data remains.
- Feedback loop quality is tied to actual user feedback volume and reliability.
- Scope is currently Lyon-focused; transferability to other cities requires adaptation work.
- LLM-assisted messaging improves flexibility but needs cost and output-quality controls.
- In the currently documented version, weather features exist in training, but real-time weather is not yet wired into MVP inference.
Screenshots and local demo
For local demos: start Docker, run the OS-specific start-all script, then open the documented services (API 8000, Streamlit 8501, n8n 5678, forms 3100, Evidently 8085).
Caption — Screenshot 1: risk map of stations to support operational decisions.
Caption — Screenshot 2: prioritized watchlist of stations likely to face tension.
Caption — Screenshot 3: forecast trends by horizon to plan actions ahead.
Caption — Screenshot 4: consolidated service-level view by station and horizon.
Caption — Screenshot 5: automated notifications to inform users at the right time.